Web
Dear Amazon Japan,
It’s great that you’ve been reaching out to international customers by making amazon.co.jp more approachable to people who don’t speak the language.
But it kinda sucks that you auto-translate about half of the product titles into Machine Engrish with no way to view the actual title without switching site navigation back into Japanese.
And your latest “feature”, attempting to auto-translate search strings into Japanese and search for that instead fails spectacularly on the simple case where someone cuts and pastes actual Japanese text into the search box.
For instance, while I can read Japanese, I leave the UI in English because I read my mostly-native language faster. So you can imagine my surprise when I pasted in “異種族レビュアーズ” and got zero search results, despite it still claiming to have searched for “異種族レビュ アーズ”. I had to find the plaintext undo button to get it to search for Japanese text as Japanese text.
After that, all sorts of results showed up, including the fact that Amazon Video is still streaming Interspecies Reviewers in Japan, and that there are manga spinoffs “Ecstacy Days” and “Marionette Crisis”. Also that the Bluray releases have been pushed back; I imagine a lot of things are being deferred thanks to Corona-chan.
Dear Amazon,
At least you aren’t blaming this one on the Post Office…
Status at 8:30 AM:
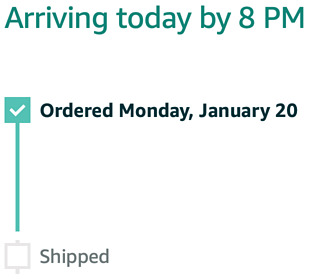
Status at 9:30 AM:
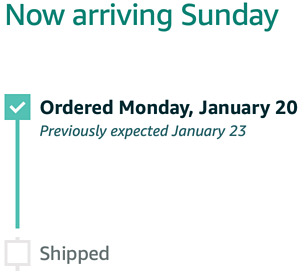
Update: Friday at 6pm…
I didn’t even need to make a fresh screenshot. Still promised for Sunday, still hasn’t shipped.
Update: Saturday at 2pm 8pm 11pm…
Still not shipped, still supposed to arrive tomorrow. Given that only USPS typically does Sunday deliveries (or at least marks it as delivered and drops it off on Monday), I’m dying to know how they’re planning to get it to me.
Update: Sunday at 8:30am…
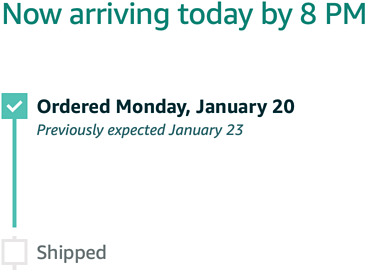
At what point does Amazon just admit they don’t have it and send the driver to Best Buy to pick one up?
Fuck it
Found it at the local Walmart for $20 less and canceled the Amazon order from my phone. This is an inversion of the natural order.
Dear Amazon,
Apparently I’ve gone too far poking fun at the results of your recommendation system, because you’ve stopped recommending anything except a few “buy it again” tiles:
-
“Buy it again in Business, Industrial, & Scientific Supplies”: Loctite, flush cutters, screw caps, and threaded screw inserts. (aka “crafting supplies”)
-
“Buy it again in Office Products”: super-sticky Post-Its, NFC tags, and inkjet business cards. (I go through Post-Its like candy; the cards are for giving the addresses of our hotels in Japan to cab drivers and luggage shippers)
-
“Buy it again in Home”: trash bags, Boveda humidifier refills, and a 12-pack of stick-on pen loops. (I only needed 2-3 pen loops, one for each Rocketbook and the third for my old Surface Pro, so it will be a long time before I run out…).
-
“Buy it again in Home Improvement”: Loctite, Loctite, stick-on plastic feet, and Philips Hue motion sensors. (seriously, Amazon, how much Loctite do you think I go through in a month?)
-
“Buy it again in other categories”: charcoal soap, toothbrush heads, USB3-to-Micro/C/Lightning cable, Gevalia Mocha Latte K-Cups.
That last one is amusing, because I actually have a subscription for the k-cups, but in a different box size, so Amazon knows I like the stuff, but doesn’t realize they’re already sending me 36 of them each month. (4 boxes of 9 is $5.65 cheaper than 6 boxes of 6)
This is my daily “liquid pie” indulgence. I drink it with two Splendas and two Mini-Moos, which is like pouring coffee on cupcake batter, yet still only 100 calories.
If I have any further coffees (instead of drinking Diet Pepsi), they consist of Gevalia or Peet’s medium-roast ground coffees, made in an Aeropress (or the new Aeropress Go travel kit) with three Splendas, a Mini-Moo, and a pinch of sea salt.
(for the AeroNerdly: non-inverted, 2 filters, 2 scoops, 2-ounce pour to wet the grounds for 30 seconds, 2 more ounces and ~40 seconds of stirring, slow press all the way down and scrape the foam into the mug, then milk-n-sugar and add 8 more ounces of water)
Dear Amazon,
All I want for Christmas is less dynamically-loaded content on your home page. Seriously, if I switch to another tab while it’s loading, half the time I’ll come back and find that Safari has given up and reloaded it. Sometimes it reloads while I’m still scrolling down. Any other page is fine.
If I turn off Javascript, it loads a thousand times faster, but then the “Recommended For You” page is completely blank. Wish lists still work, although you have to dig a bit to find them.
This all seems to have started right before Black Friday. Perhaps dialing back on the poorly-debugged holiday scripting is in order?
Dear Amazon,
I love that you’re promising next-day delivery on a lot of items, but in your relentless pursuit of shipping optimization, you have failed to take into account the fact that USPS simply lies about when they “delivered” a package.
For instance, Wednesday at 5:53 PM, I placed an order (“free next-day shipping, for sure!”). Tracking shows that you handed it off to my local post office at 4:44 AM Thursday. USPS claims it went out for delivery at 8:44 AM, and was placed in my mailbox at 6:51 PM. My mailbox (of the shared, locking variety at the curb) was completely empty when I got home at 9:15 PM.
This is not the first time this has happened. Sometimes it shows up on my porch very early the next morning, other times as part of the next day’s regular delivery, occasionally delayed even further by a weekend or holiday, and at least once it never turned up at all, despite being marked “delivered”.
Friday night update
By golly, the “delivered Thursday” package somehow found its way into my locked mailbox today! It’s almost like it never made it onto the truck and they checked it off to pad their numbers!
Oh, wait, it’s exactly like that!
Dear Youtube,
Twice in the past few days, I’ve had a video interrupted in the middle by an unskippable video ad for an unrelated and uninteresting product.
So I downloaded them and watched offline with no ads at all.
Fun with Chrome
First, if you haven’t already stopped using Google Chrome, stop now. What could possibly go wrong with allowing web sites to edit files on your computer, and have your mobile browser automagically process those annoying two-factor-authentication SMS messages and agree that it’s really you logging into your banking site?
Security? They’ve got Top Men working on it right now!
An update for Chrome 78 is now available that fixes two major security vulnerabilities, one of which is already being used to exploit devices.
Weasels gotta weasel
It is indisputable that the Google Chrome updater crashed thousands of Macs, primarily those used by video production studios. FFS, the smoking gun is right there in their updater logs:
GoogleSoftwareUpdateAgent[1213/0x7fffc9d683c0] [lvl=3] -[KSLockFile(PrivateMethods) deletePathIfSymlink: except: ] Found and deleted symlink at path /var
And it logs an error message if it can’t delete /var, which means nobody in Google QA reviews log errors before saying “ship it!”.
But how did they spin it? (emphasis mine)
“a Chrome update may have shipped with a bug that damages the file system on macOS machines with System Integrity Protection (SIP) disabled”
There are reports that it has affected people who have SIP enabled, which seems to be due to them having gone through multiple OS upgrades, starting from a version that didn’t have SIP, with permissions somehow getting changed from the defaults over the years.
The reason it hit video studios so hard is that they were all running external Thunderbolt 2 GPUs to accelerate Avid, and to run the required unsigned kernel drivers, they had to turn off SIP.