Fun
Unexpected presents...
Amazon Interstellar

Childhood’s End
No, not that one. This one. Of the many pop-culture references from the Seventies that have been converted to LoRAs, this is not one I intend to pursue.

Blackout
My patience is rewarded, as the 15-year-old overpriced Connie Willis novel finally drops below $10 on Kindle.

Merry Christmas from The Cheesecake Faptory
Tear off the wrapping paper and enjoy!
[Update: just realized I made the "-small" versions full-4K as well, which was silly. Page should load a lot faster now...]

Note that my new workflow is built around my SwarmUI
CLI, which
now correctly preserves metadata even when generating to JPG, so the
large images have the full parameters embedded in the EXIF User
Comment field, making it possible to drag them back into SwarmUI or
just view the prompt and other settings with exiftool:
exiftool -b -usercomment cheesecake.jpg | jq .
Lazy meme day
Same vibe

The M in M1911 is for…

Last Christmas

Peak Japan

Related,

Modern dating
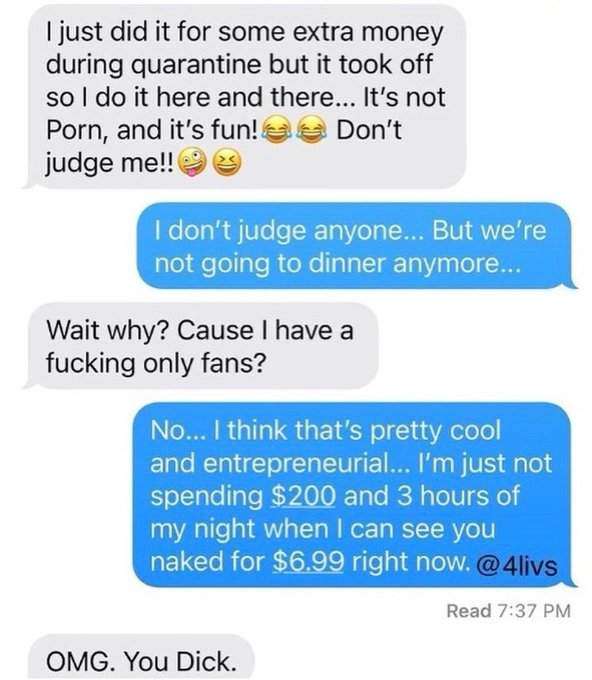
Life goals

Life lessons
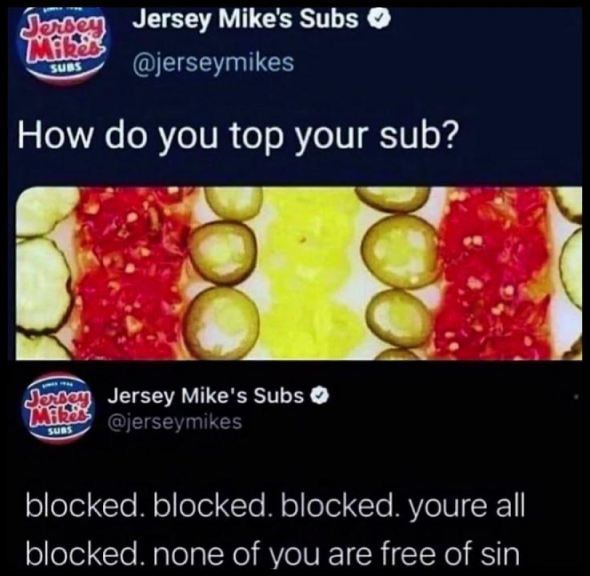
“Lucy, you ignorant LUT!”
Fallout Season 2, episode 1
“Let’s set up an entire season of convoluted plotting all at once!”
IMHO, Walton Goggins is the only thing holding this together, and spacing it out so you have to watch one episode per week like our primitive ancestors did does not enhance the experience. I’d prefer to just rip off the bandaid and get it over with, but that won’t be possible until February.
Maybe I’ll watch the rest then.

(I did not use the word “alien” to describe the creature, because that word is strongly associated with a very specific overused image of a pop-culture alien, just like asking for “alien symbols” gets you an Alienware logo; creature, monster, pretty much any other word is a better choice with most models)
(also, this is probably the best-looking pistol I’ve gotten out of ZIT, and it’s even in a decent “holstered” position)
LUT-shaming
Random image is random; I’m experimenting with adding a LUT post-processing pass to my SwarmUI CLI, to fix Z Image Turbo’s slightly flat colors. The output looks fine on its own, but when I mixed some of its cheesecake into the wallpaper rotation, you could really see the difference.
If anything, the pics from Qwen Image were too saturated, but for some of them that was part of the “vintage airbrush pinup” look I was going for with them. My first pass at cleaning up the ZITs was doing a basic auto-level-ish command with ImageMagick:
magick $file -contrast-stretch 0.15x0.05% new/$file
Worked great, but it would be nice to have it run server-side, before
JPG compression, and the recommended method is to apply a LUT. There’s
a whole suite of post-processing
tools available
as a SwarmUI extension, and plenty of free LUTs online
(1,
2,
3,
etc). You can also copy .cube files from any professional imaging
software you happen to have a license to, such as Photoshop, where
they’re usually named by the film/camera look they apply.
Raw from ZIT:

I think the Fuji Sensia LUT pops the colors a bit without going overboard:
 realistic illustration in the style of boris vallejo. two cats dancing in the alley of a ruined city.")
(best part: applying a LUT adds basically nothing to rendering time, and generating a comparison grid of every installed LUT at different strengths takes seconds, since the server can reuse the rendered image and just apply each transform in turn)
Another pair of cats dancing…
Okay, they were both pretty cool cats, but not quite what I had in mind.
It's beginning to look a lot like Shipmas
…although with Amazon having forgotten most of what they ever knew about logistics, Shipmas is a bit like Schrödinger’s Cat Box, with things never showing up as trackable until two days after they were promised for delivery, which is always fun to explain to kids.
Fun(?) with Liquid Ass
iOS 26.2 is out, so one could hope that other customers have done the basic release QA for Apple by now. I wanted to see what the legibility looks like, to see if it’s safe to upgrade my mom’s phone yet. So I installed it on my old California phone, which doesn’t tie into any online services (do not upgrade a device that uses iClown until you’re ready to upgrade everything; they test cross-version compatibility even less).
TL/DR, no, doesn’t look like they’ve finished tuning the UI to restore readability. It’s better than the initial “release” (beta), but still not good for anyone with less-perfect vision than an Apple design team.
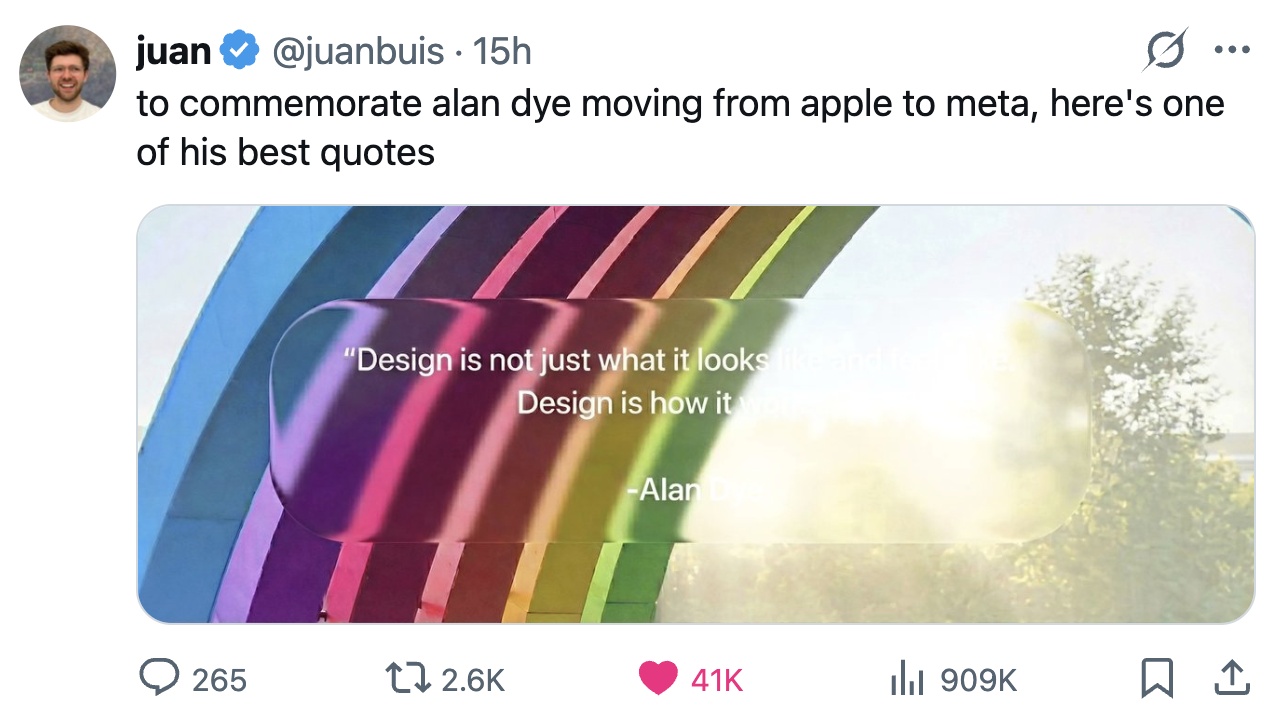
Synology pivots to “AI”
Their latest device is BeeDrive, an “AI-powered Portable SSD”. Not to be confused with their BeeStation “private cloud”, which is not to be confused with their NAS products. As far as I can tell, none of the Bee-thingies has any data protection, although the Station offers a free trial of “storing bits of your private cloud in their public cloud”.
TL/DR, both product lines appear to be external drives that come with backup software, which is a pretty crowded market. On the plus side, they didn’t roll their own, and licensed Acronis True Image (“formerly Acronis Cyber Protect Home Office”, signaling that they’ve (partially) recovered from their childish phase of labeling everything “cyber”).
On the minus side, they’re bundling an offline LLM to do text-scanning, image-scanning, and inference on everything you store, for Deep Search(TM). So when the local authorities decide they don’t like your memes, they can sieze your backup drive and quickly find additional double-plus-ungood thoughts to charge you with.
I mention this for the benefit of those living in Australia, the UK, Canada, the EU, and other regimes hostile to free expression of disapproved thoughts.
I also suspect their LLM is going to produce hilarious results when fed a typical Internet user’s hard drive. Most common search result:

(primary difficulty on this one: getting separate speech bubbles with one of them coming from the computer; maybe six tries total)
Definitely not a “1-minute walk”…
A Kyoto “tourism site” describes access to the Sannenzaka shopping district with the words “A 1-minute walk from Keihan Railway’s Gion-Shijo Station”.
Google’s walking instructions suggest they left off the first digit, and it’s not a “1”…

Given how sparse, generic, and monolingual the content of the site is, I suspect it’s AI slop. Which is why I’m not linking to “kyoto-to-do dot com”.
Speaking of slop…
My phone is now getting computer-filtered 50% Medicare/Medicaid fraud and 50% home-improvement fraud. I need to answer the phone for unknown numbers while I’m expecting service providers to show up, so I can’t just let them go to voicemail (and even legit numbers often don’t leave messages any more).
I say “yes” to get to whatever operations center in India is taking the calls today, and then ask them a simple question: “what’s my name?”. If they have even the cheapest possible call list, then they have some name associated with my phone number.
But none of them can answer, and they stop talking immediately and hang up.

GenAI Girl Trouble
This week’s SwarmUI Discord theme is food. Z Image Turbo nailed the concept on the first try, but I made a few more until I had one where she was carrying the pepperoni in both hands.

(the first time I tried to upscale this, I got a bunch of extra extra-tiny people scattered around the image. Turned out that the “refiner do tiling” option was on (legacy of a more memory-intensive model), and it was generating additional people on each tile, at the appropriate scale; first time I’ve seen it do something like that)
Captions, on the other hand…
The “New Yorker” look was easy, given the artist name and a style description, but getting every word right remains a challenge for diffusion models, even when you avoid rare words. Part of the problem is that for all its virtues, the turbo part of Z Image Turbo means that it does 90% of the work in the first pass, which doesn’t leave as much room for variation and refinement. It took 10 tries to get 2 correct captions, one of which was rendered even smaller than this one.

The WWWA Central Computer says “get off my lawn!”
Dirty Pair 40th anniversary merchandise.

Global warming coming down
We were promised hours of snowfall starting at 1PM, so I made an early-morning run down to Jungle Jim’s for some holiday food shopping. I got out of there around 10:45AM, at which point it was just starting to sleet.
Getting home took twice as long as the trip out, because there were already several accidents on the highway, despite the fact that the roads were still clear and there was no ice.
I made it home as it started to snow just enough to require my windshield wipers, and soon after I got the car unloaded, the sky unloaded.
Boy, bet those Amazon drivers wish they’d delivered my packages yesterday as promised, rather than leaving them on the truck and taking them back to the depot for the night…

Peternal
EXIF is such a mess of a standard that the best way to work with it in
Python is a thin wrapper
around the exiftool command.
Which is a Perl script.
, shantae, ベリーダンス")
Coffee Dump
James Hoffmann explores the depths.

The Complete Winter Season Preview!
- Frieren 2: Yes.

(anything else, I’d first have to watch a previous season that I skipped, and I don’t know if the hot adorableness of Torture Tortura is enough to compensate for Shouty Princess Shouting)
Dear PILs,
Whoever thought it was a good idea for Pillow to silently strip metadata should be pixelated with extreme prejudice.
Also, could ya maybe flesh out the documentation a bit? I would not
know that you could add exif=somedict or pnginfo=somedict
arguments to Image.save() if I hadn’t googled examples. Just knowing
about the existence of those arguments would have helped explain why
one of the two save paths I was using was metadata-free.

“I don’t see you in our system…”
Called the home-security company to have them come out and install new sensors on the replacement doors. After suffering through a really annoying hold system, the woman who answered had no record of my account. Until I mentioned the name of the company, at which point it turned out they’d been acquired, and their phone number was transferred over to a new central dispatch system on Friday. After she logged into the correct system, she… copied down all my information by hand, because that didn’t work either. I’m supposed to get a callback, eventually.
Really doesn’t make me optimistic about their responsiveness to alarm calls.

“I don’t see you in our system…” 2
Due to a recent acquisition that should be all over the news for the business we’re in, my team is being added to their legacy IT systems; email, VPN, Jira/Confluence, etc. The Belfast team got all their invites Monday, but I got nothing. I figured they were going by region, and I pretty much am my region, so I didn’t worry about it.
The good news is that I finally got my first notification about access.
The bad news is that it was for Teams.
, 阿良河キウィ")
“so much glitter”
My Mac suddenly decided that I couldn’t open certain images and PDF files, claiming a permission problem. The well-written error message even told me how to fix it, which of course didn’t work, because it had misdiagnosed the problem. I could open the files, just not with Preview.app.
It would open 90+% of files just fine, but consistently fail on others. TL/DR: Preview.app leaks resources over time, and I’d been keeping it open because otherwise it loses my place in the PDF file I’ve been reading.
It’s not supposed to do that, either.

(in fairness, I’ve opened and closed thousands of images over the past week, often a few hundred at a time; why they wrote Preview to open all of them simultaneously, I can’t imagine, but they did. This is one of the reasons I “vibe coded” deathmatch)
Unrelated,
I am convinced that every air-fryer manufacturer staffs their cooking-guide team with people who have never seen a pizza roll. One of my Black Cyber Fortnight purchases was a Ninja Crispi Pro, and the recommended time and temperature for a bag of pizza rolls is 10-15 minutes at 450°F.
I have never seen a pizza roll survive more than 8 minutes at 375°F without bursting open and spilling out its precious lava. 10-15 at 450 is crispy-critter territory.

(okay, this was not the direction I expected Z to go with this, but I find myself unable to complain)

(discussing the previous pic on the Discord eventually led to a non-serious idea about an in-person gathering to make late-night drunk snacks)
Finally!
The key to unlocking proper pizza rolls in Z was to avoid any word that could be mistaken for Asian cuisine. “roll” means egg roll, “dumpling” means gyoza or shumai, etc; “deep-fried pillow-shaped miniature pastry” dodged the over-training bullet.

(yes, “chicken and dumpling soup” produces a thin broth with gyoza and sliced chicken floating in it; harrumph)
Feel the Uravity

(not only does she defy gravity, but also Internet Wisdom about the plausibility of the boobs-and-butt pose)
Sick weekend
Literally, in a “let’s not ask genai to illustrate that” way. Feeling much better now, but I lost nine pounds in a day and a half, and I would not recommend this weight-loss plan.
Streams: Crossed
The Kpocalypse Kometh!
KPop Demon Hunters to Ring in Dick Clark’s New Year’s Rockin’ Eve
No, I will not be watching. Not because I bounced hard on the obnoxious trailer for KDH, which I did, but because I’d rather scrub the toilets than “ring in the new year” with a live TV broadcast. My traditional New Years festivities include ordering delivery pizza, tipping heavily, and avoiding all human contact. Admittedly, it’s the same as my plan for most holidays.

(no kpop artists or undead pop-culture icons were harmed in the faprication of this genai image)
Dear Amazon,
What’s the customer-support code for “driver too lazy or stupid to walk 20 feet to the front porch”? Trick question, I know, because there’s no button for reporting on the quality of a delivery. If I navigate through “customer support” I eventually get redirected to a 20-minute-wait “chat” screen, but the odds that an English-speaking human being will respond are… “less than promising”.

Thesis
“90% of improved coffee-making technology is just baristas pretending they’re Tom Cruise in the movie Cocktail”

How to reduce memory use in Discord
I never knew that Discord was such a memory hog, to the point that it now auto-restarts when it gets above 4GB. I just got in the habit of exiting it after every session because writing a desktop application in Javascript produces a terrible user experience and is guaranteed to come with giant gaping security holes.
And you don’t want giant gaping holes exposed on the Internet.

Related,
Z-Image Turbo is so popular that even the amputee fetishists are rushing to make LoRAs catering to their specific sub-kinks. Kinda wish they weren’t, actually.

(people are raving about how easy it is to make LoRAs for ZIT, but most of the SFW styles seem to just be adding keywords to styles the model can already produce. I didn’t use any LoRAs for the above images, just long style descriptions followed by relatively short prompts (see mouseover comments))