“Broken gets fixed. Shoddy lasts forever.”
— Unknown developer, quoted hereDear Uber,
It’s fine that you think I need a side gig, and I’m sure you mail this to a lot of your used-Uber-only-once customers, but I think I should point out that this deal is not the least bit attractive for someone who lives two hours south of San Francisco. And that’s with little or no traffic.

Dear Marvel,
Please make the next Spiderverse movie 90% Peni.

…and 60% Gwen.

Also, please make the next Spiderverse movie.
Catting around...
Still collecting interesting places for our upcoming trip to Japan, and I found a cat café not far from our hotel. No catgirls, no moe maids, just cats. Since I no longer have any active porch cats, this will be a nice diversion.
Dear Woot,
Please don’t screw it up this time.
(last time they sent a charger for the wrong generation, then ran out before they could exchange it; I got a refund, but I really wanted the charger…)
3/13 Update
Thanks, Woot; this time you sent the right charger. Why did I care about an N-generations-old Windows tablet? Well, first, because it has a Core i5, 8GB of RAM, 256GB SSD, HiDPI display, and the good pen, so it’s still quite a useful gadget, even before you take into account the fact that I have both the extended-battery US keyboard and the backlit Japanese keyboard.
Second, because quite a while back, Microsoft recalled the power cord (not the brick, just the part that went into the wall) due to thermal issues, but they had no provision for replacing a second power supply if you’d bought one. And I’ve long been in the habit of buying an extra when I plan to commute with a system. That left me with one known safe power supply and one that I couldn’t risk leaving unattended.
Getting a new OEM charger for less than what a fly-by-night Chinese company with a randomly-generated name charges on Amazon was a no-brainer.
Baby, should I have the baby?
Today’s ACLU Top 40 Flashback:
OpenType font mapping woes...
It seems the font bug I ran into when making
calendars has opened a can of
worms.
PDF::API2 is only lightly maintained these days, but there’s active
development on the fork PDF::Builder, and the dev saw my bug report,
cloned it into his project, and started poking around. Original module
author Alfred Reibenschuh chimed in, and after some back-and-forth, it
looks like the glyph-mapping code pretty much needs to be ripped out
and rewritten from scratch.
I have a hunch I’ll be tasked with producing a CJK test case, which means I’ll need to collect some Chinese, Chinese, and Korean samples.
Thanks for clearing that up...
They said this. They really did.

Update: Keep digging, Trump needs more votes!
The batshit-crazy is strong in this one…
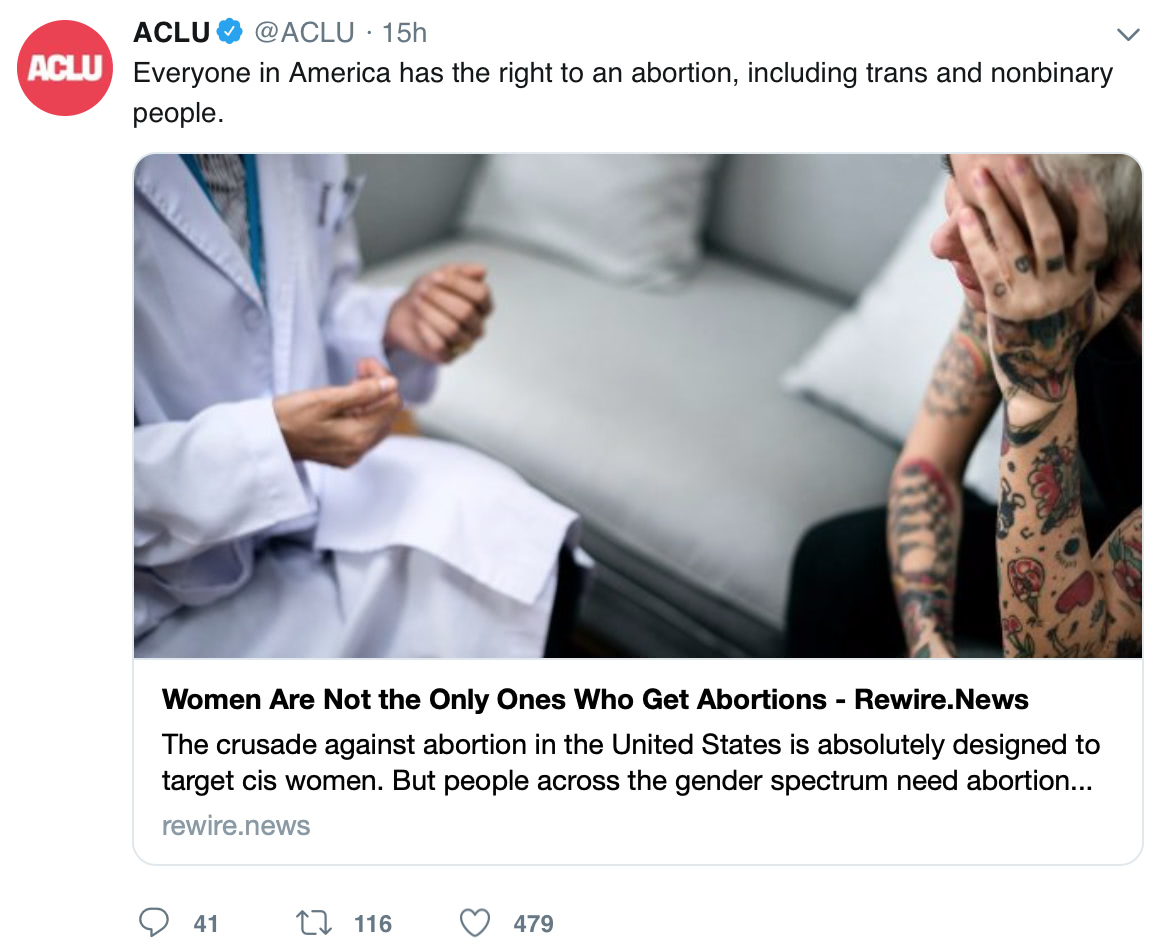
This may be the most imaginary oppression in the history of imaginary oppressions.
tee-hee
Apple's closed ecosystem...
Part of my vacation planning is building up map bookmarks to share with my sister, so we can go off on separate adventures and easily meet up later. I have a bunch of old Google Earth/Maps bookmarks from previous trips and planning. I also have a bunch of Apple Maps bookmarks from recent planning. (why? Because Google no longer supports the standalone Google Earth app, and wants you to run it in Chrome, which logs you into your Google account so they can track you across the Internet)
Google lets you export any number of saved places to an XML file.
Apple lets you share one bookmark at a time to specific
applications, but only as a URL pointing to maps.apple.com. For more
fun, on a Mac your bookmarks are stored as an opaque binary blob in
~/Library/Containers/com.apple.Maps/Data/Library/Maps/GeoBookmarks.plist,
along with a cached copy of their data about the location. You can
reorder this list inside the desktop Maps app, but that order will not
be respected on iOS.
Extracting 35 bookmarks meant creating 35 notes in a supported app, then copy-pasting them into a text file and extracting the “q” (name) and “ll” (lat/lon) fields.
Seriously, Apple?
Update
For future reference, to convert KML to straightforward CSV using togeojson and jq:
togeojson $kmlfile | jq -r '
.features[]|select(.geometry.type == "Point")
| select(.properties.name)
| [([.geometry.coordinates[1],.geometry.coordinates[0]]
| join(",")),.properties.name,.properties.description]
| @csv'
Update
So, you can get your Apple Maps bookmarks as a CSV file, but only by using Apple’s privacy page to request a copy of all data Apple has on you, and waiting about 5 days for them to package it up.