Web
That was new...and pointless
Someone posted two comments to the previous entry that were filled with links to his (or his customer’s) web site. File that under bafflingly stupid, since search engines don’t execute Javascript when they index content, and my comment system is JS-only.
It was adorable, too, with every letter a separate link to a page on the site. Judging from the URLs, it’s a clickbait site aimed at an English-speaking Indian audience. Must not be very good clickbait, if they’re desperate enough to hire an inept pagerank scammer.
Dear US Customs Department,
Please update your Javascript validation code on the Global Entry application page to accept brand new passports issued during the current month.
Update
Works today. Someone must have noticed before I did, because I sincerely doubt that a government agency could make, test, and roll out a change to a web site on a Sunday night.
Now to see how long the queue is.
Blog software update
I bit the bullet and upgraded Hugo finally, from 0.41 to 0.53. Why so far? Because in 0.42, they re-did the internals for making relative references to pages by name, and made it a fatal error if pages in completely different sections had the same filename. Even if you never actually referenced them.
This was a show-stopper, because the only way to build your site was to fix all filename collisions, which meant breaking external links. In my case, about 300 of them on the blog, and several thousand on the recipe site (which, being automatically generated based on the recipe name, was hard to deal with; why, after all, shouldn’t two completely different collections be able to have a recipe named “egg-salad”?).
After some back-and-forth, they made it a warning that such references will return non-deterministic results, but by then there had been other changes that affected output, and I always do a full diff of the site to catch undocumented changes. And the diffs kept getting bigger.
Today I finally broke down, renamed all the colliding entries in my
various microblogs (mostly affecting external links to the Quotes
section), and scrolled through the 93,923 lines of diff output.
Fortunately, 95% of it turned out to be removal of a bunch of
gratuitous <p></p> pairs inserted by the old version of their
Markdown library (either completely empty, or around <div> tags).
Looks like they actually undid some of the changes that had increased
the diff size for earlier versions.
As far as I can tell, nothing noteworthy broke, so I’m back in sync with the devs, and I’ve shaved a few seconds off my build time again.
Yeah, that'll work!
Dec 17: Tumblr removes adult content.
Dec 24: Tumblr shuts down completely.
Seriously: “photos, videos or GIFs that show real-life human genitals or female-presenting nipples” is about 95% of their content. The rest is emo kids and SJWs, who aren’t going to provide much ad revenue.
Needs a bit of work...
Tim Berners-Lee announces new decentralized web technology. Site immediately crashes under load in classic slashdotting.
Update
If you bypass their overloaded web server and go straight to the github repo, you’ll find a slumgullion of kitbashed code and obsolete documentation, suggesting that the simplicity and elegance of Berners-Lee’s earlier invention are completely absent here.
Dear Amazon,
So, I stumbled across the link that takes you to the old Items you’ve marked “Not interested” page, and by golly, my 50,000+ entries are still there, and are still being updated with new entries.
You’re just not using them to filter items from the current “Recommended for you” tiles.
In fairness, there’s a bit of load associated with slurping in 50,000+ ASIDs every time I visit the site, but you could at least use the most recent 100, and either make it possible to bulk-edit the list or simply wipe it. The old recommendation used to be “create a new Amazon account”, but that’s not practical now, with Prime, Kindle, FireTV, etc.
PhishedIn
A number of people at work had this pop up in LinkedIn:
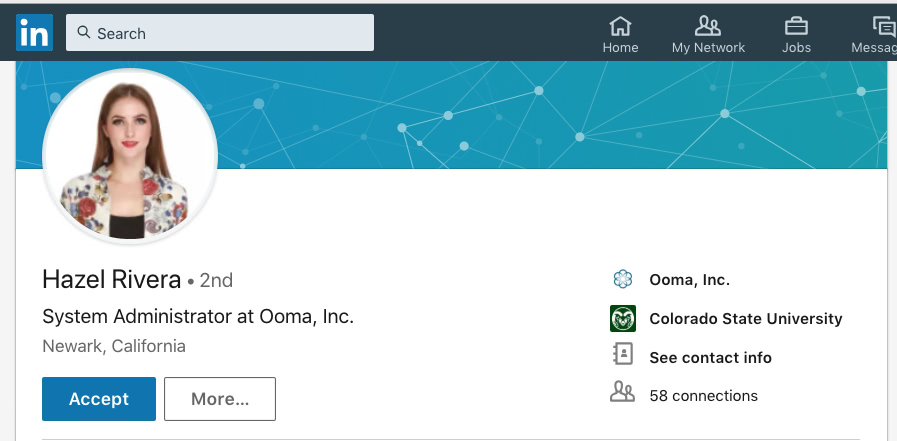
Many of them cheerfully connected to her. When it hit folks in IT this morning, though, everyone responded with a cheery “WTF?!?”. No one by that name has ever worked here, in any department, and certainly not the dates she claims. We flagged it as phony, and the profile has now been deleted.
I was curious to find out where the photo came from, since it had that artificial posed look commonly found in stock photos and catalog shoots.
Sure enough:

I cropped the screen-capture down to a head-and-shoulders shot, but Google Image Search came up empty, so I tried TinEye, who matched it with a small copy of this photo on price-hunt.com. I fed that URL to Google, and it came back with an Amazon India product page that had a larger copy and several more.
Kudos to TinEye, since I only gave it a ~120x120 copy of the top third of the picture.
Dear Amazon,
Once upon a time, there was an actual “things you’ve marked ‘not interested’” list that could be added to, and even edited (unless, like me, yours had more than 20,000 items on it).
Now, however, your recommendation system has no memory at all. How else can I explain being offered the exact same items that I select “I’m not interested in this item” for every damn day? No, I do not want a Funko figure of Nearly-Headless Nick, and I won’t change my mind when you ask me again tomorrow. No, I do not want to read book 6 of an isekai series about a slime. No, I don’t want a Funko figure of Inigo Montoya, because I already bought the damn thing last week!
Seriously, of the 50 items in the “New Releases” you just offered me, I’ve already rejected 42 of them, some of them half a dozen times. If the buttons don’t do anything any more, just remove them and stop pretending you’re paying attention to my preferences. And understand that you’re selling less stuff to me because you’re not showing me products I might actually want.