“There was a small number of really smart, really young coders who produced a lot of very clever code that only they could understand.”
— Guido van Russum explains Dropbox's core problemPorch Cats: Scrawny, Tubbs, Smoky
I’m up to five regular visitors, and the most common ones are getting comfortable enough that they don’t vanish over the fence when I open the front door. Instead, they wait to see if I’ve got a bag of food in my hand, which has allowed me to get a few pictures with a real camera.
Scrawny
Queen Of The Chairs, she’s out there almost every day now, and has become bold enough that she’ll let me get within three feet as she waits for the food and water dishes to be filled. She doesn’t like me, and will hiss if my hand gets within about a foot, but she’s the boldest of the lot.

Tubbs
Like his Neko Atsume namesake, he’ll eat everything that I leave out if nobody beats him to it, and I often see him making the rounds from porch to porch. Fortunately, he seems to have a lot of places to visit, so most days the other cats get food.

Smoky
I’m stunned that he refrained from fleeing long enough for me to get even one in-focus picture.

Whitefoot
Terribly shy, and mostly comes around after dark, so I’ve just got
night-vision footage from the Arlo Pro cameras. Part of that same
litter I found two years ago, and the
first to spend a few days lounging on the chairs. That’s still the
only decent picture I have. Update: finally got a good
picture, and it’s not the same cat.
Caramel
Scrawny claimed his chair during the day, so he mostly comes by at night now, when nobody else is around. The others all seem to get along if nobody challenges Scrawny for the chairs, and I’ve got lots of late-night footage of them just hanging out together on the porch. Still no good pictures of him, just the one where he was hiding in the bamboo.
What’s missing in all of these pictures is any hint that they’re housed anywhere. They’re healthy, but they don’t have any tags or collars, and after the rains ended, Tubbs was pathetically grateful for the self-refilling water dish I put out. And they’re not socialized; Scrawny is the least skittish, but reacts violently to any attempt at contact. In his kittenish days, Whitefoot sat on the chair and purred, but now vanishes in a heartbeat if I start to open the door.
Cheesecake: Creayus
I liked the above-the-fold image from the previous cheesecake post so much that I went looking for more by the same artist. Often when I do this, I discover that the image I liked is a rare gem buried in a sewer (like the one artist who took his most attractive creation and drew her taking a dump; yeah, not going back there again).
The image I liked happened to be of CC from Code Geass, and it turns out that’s 90% of what he draws. Even many of his drawings of other characters are just CC in cosplay. Not necessarily a bad thing, unless you’re marathoning the whole collection to pick out a few dozen.
 hair_ornament hairclip kantai_collection pantyhose skirt smile solo thighhighs")
QFT...
What’s your social justice super hero name?
[your undiagnosed mental illness]
+
[The weapon you used at your last peaceful protest]
(via)
Cheap Hunie
HuniePop and HunieCam Studio are deeply discounted in the Steam Summer Sale for another 24 hours, at $2.49 and $1.74, respectively. I found them both quite entertainingly naughty (or naughtily entertaining) games.
A cool 18th of Moa to all
2017/07/04: 9am, 55ºF outside; projected high, 69ºF.
I just turned on the gas fireplace to take the damp chill out of the house. The prevailing wind direction makes a huge difference in temperature and humidity around here.
Also, happy 18th of Moa, which Google search inexplicably celebrates with a “4th of July” image that’s red, white, blue, and animals commonly hunted in North America.

Mini-Review: Sakura Dungeon
WARNING: as published on Steam, Sakura Dungeon is NSFW. As augmented by the free patch, the art includes hardcore porn. It’s also on sale for $12 as part of the Steam Summer Sale, along with all the other Sakura games (all NSFW, but only about half with explicit patches).
Developer Winged Cloud is a bit of an oddball, since their only web presence is a Patreon, and everyone who used to publish their games broke up with them a while back, so there are a lot of dead links out there.
Sakura Dungeon is apparently their most ambitious title, with a full
RPG dungeon-crawler layered over the standard dating-sim kinetic
novel core common to their other titles. The PoV character is a
fox-spirit (female) trying to take over a dungeon full of monsters
(female), with the reluctant help of an adventuring knight (female).
Naturally, all of them are young, busty, and cute as buttons.
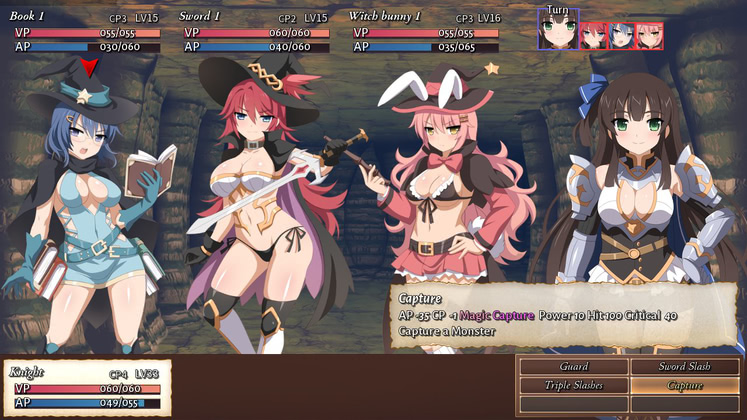
(via, apparently from a pre-release copy, since the names are incorrect)
The dungeon is a strict grid, with only a few different images for each floor type. The puzzles are pretty simple and occasionally tedious, the loot is unimpressive, and the combat is straightforward turn-based point-and-click.
So why play? Because the characters are fun, the story is shallow but engaging, the girls are gorgeous, and the combat is full of Most Common Special Attacks that blow their clothing off. And not being a Japanese title, there’s no loli, no oddly-specific fetishes, and the closest it gets to non-consensual sex is “aw, c’mon, it’ll be fun”.
Why did I buy it in the first place? Because I kept seeing this picture around the net and finally found out where it came from:

Update
I apologize for misusing genre jargon above. I’ve tended to lump all of these sorts of games together as “dating sims”, but while that may be their most visible manifestation, it refers to a set of relationship-building mechanics that are not present in all such games, and is orthogonal to the distinction between “visual novels” (where the player has choices with consequences, the old choose-your-own-adventure paperback) and “kinetic novels” (where there’s only one narrative thread, what we used to call “novels”). Most of the Winged Cloud games are kinetic novels where your choices boil down to “watch them fuck” or “don’t watch them fuck right now”.
There’s only one narrative thread in Sakura Dungeon, and you can only fail to achieve it by losing fights in the dungeon, not by making choices in the narrative. There’s no point in the story where the PoV character can choose between “take over the dungeon” and “perpetual orgy in this town full of sexy girls who worship me”. There’s also no stable management or relationship manipulation, like a raise-the-princess game or dating sim; if you catch a monster girl, she will join the party, and any improvement to her fighting ability is determined by using magic items with predictable effects (“raise agility”, “increase fire resistance”, “learn shockwave”). Who’s in your party affects only your combat ability in the RPG and some one-liners in key fights (with a few exceptions where a character is required to unlock a cutscene).
So that makes it a kinetic novel where progress is gated by an RPG/MCSA dungeon crawl, with unlockable “watch them fuck” cutscenes.
Amusing note: I’ve been playing around with the popular Ren’Py engine, swiping art assets from Sakura Dungeon to “kineticize” my old Hero meets Villain story. It ends up being about four minutes long, which makes a useful comparison to how much story is in a Winged Cloud game that takes 2-3 hours to play.
Update 2
Thanks to unrpyc and some quick regexing, it looks like there are
roughly 138,000 words of text in Sakura Dungeon, making it a
good-sized novel. Selecting a few at random turns up such literary
gems as:
- “I like it when people lick me all over…”
- “If you apply magic to it correctly, it can hold its shape yet remain fluid…”
- “I care not what I whip, only that I am whipping.”
- “We cannot let that panda roam freely.”
- As we step into the room, we find that we’re surrounded on all sides.
- “Sorry, but I really want to see you in a maid outfit.”
- “Oh… You’re one of those…”
- The chocolate absorbs some of your mana and replenishes itself.
- “That rabbit is going to learn a painful lesson.”
- I can only imagine having so much attention from so many cute, luscious women…
- “Please come back later if you would like to use our services.”
- “It’s not a real tail.”
- “I wonder what sort of things they have on-board for stimulation!”
- As it slides into me, my body shudders from the sensation.
- “Can we cuddle, at least?”
- “We should do this again sometime!”
- “Please don’t go wandering off by your-”
And how could I forget:
- In the popsicle goes again.
Too late, Darwin, too late
The story of the 19-year-old who killed her boyfriend while trying to make a Youtube video sets a new record in “hold my beer and watch this” stupidity, while both shooter and shot were cold sober at the time.
-
He convinced her it was safe, because he’d shot at a book before and the bullet didn’t go all the way through it.
-
She believed this claim.
-
He held the book against his chest.
-
She shot from one foot away.
-
With a .50 AE Desert Eagle.
-
With their 3-year-old daughter nearby. (do the math, 18-year-old knocked up 15-year-old that he started dating when she was 13)
-
While pregnant with their second child.
-
All of this was announced in advance, both online and to friends and family, who couldn’t talk them out of it but took no steps to actually stop them.
The words “tragic” and “accident” are twisted out of shape to cover this dangerous, reckless, deliberate, stupid stunt, which was designed to make these two imbeciles Youtube celebrities.
Predictable “if only we had more gun control” arguments are being made, but fall to pieces if you so much as breathe on them, because people stupid enough to do this are doing other stupid things. If she hadn’t killed him, they’d likely have killed their daughter eventually with carelessly stored household chemicals, matches, etc.
Fight Pad, Elfless, Bill's Star, Demi surprise!
DanSora 12
Ok, I was wrong about how the last two episodes would play out, because there was only one. And yet somehow they ran out of story and padded it out with multiple exposition scenes that explained all the details and implications of what just happened. At least Aiz’s seiyū finally got to show emotion for more than a split-second, even if it was limited to rage.
Seriously, even Finn is jacking off to Bell’s heroic spirit now?
Eromanga-sensei
I didn’t realize last week was the finale, because it didn’t end so much as just stop. Fun little series, but I guess the source material didn’t have an obvious spot to end the season. I presume fistfulls of cash have been waved around for a continuation, so they didn’t really think it was necessary.
Doctor Who 10.12
I have no words. No, that’s not true. I have a lot of words, but they’re not very nice, and I don’t want to clean spittle off my screen. On the bright side, at least I got my wish; she was dry and showed emotion.
In the middle of the episode, my Amazon Echo thought it heard the Doctor ask it to tell a joke. This turned out to be more entertaining than the actual dialogue. Perhaps next time he should ask for a decent storyline.
I think the best way to understand this season is as a metaphor for suicide. The trailer for season 8 boasted, “I’m the Doctor. I’ve lived for over 2,000 years. I’ve made many mistakes, and it’s about time that I did something about that”, but he never does. Instead, he becomes more and more self-destructive, even trying to throw away all of his future regenerations by jumping into a rift to hold back a trivial threat.
It’s a chronicle of hesitation marks and cries for help. He’s torn between wanting to end it all and wanting someone, anyone, to save him. Which is Missy’s role, the frenemy he calls in the middle of the night after swallowing a bottle of pills and slitting his wrists (“across is for attention…”).
So maybe I did have a few things to say without spitting. Much. 😄
Demi-chan 13
This more than made up for the weak end to DanSora, the possibility of several seasons without Elf, and the cut-and-paste DW climax that had the emotional impact of a cheese dip recipe. Demi-chans are always welcome. More, please.