ZIT A/B tests
Random pointless product alert
Oura, maker of smart-rings that have 7-day battery life, has announced a new portable charging case capable of 5 full recharges. I’m not sure how large the off-grid-for-more-than-a-month market is for a fitness ring.

(picture is probably unrelated…)
Anyway,
There have been several attempts to add detail to Z Image Turbo’s barbie-doll nudity, both as LoRAs and as full model checkpoints. Most of them have not only failed to deliver on the promised parts, but their training data wrecks the faces, and often the general functionality.
My initial tests with Z Image Turbo By Stable Yogi suggested that if you weren’t asking for nudity, the output was usually nearly identical to the original model, and it played well with existing LoRAs trained against it.
There were some interesting differences. Regenerating my square-peg pic changed the scene significantly, and some other regens had easily-visible changes, but I wanted a controlled test with no LoRAs. I used my standard batch vertical wallpaper settings and fed 20 random prompts to the original model, then fed the same parameters back through the script, changing only the model name.
Even with identical seeds, the sampler I’m using introduces a tiny bit of randomness, so I expected minor changes that wouldn’t invalidate the test. (note: next time, use standard Euler instead of Ancestral to eliminate that)
TL/DR: I can’t pick a clear winner based on this sample. Sometimes one was clearly better, sometimes the other, sometimes I liked both. And of course, some of the pics just didn’t work out.
Click to embiggen…
1

A: better clothing texture and long hair. (why shamrock earrings and shoes? literal interpretation of color-word “clover-green” in prompt)
2

B: better head proportions and background detail.
3

B: smile, catchlights, slightly thiccer, slightly more lively background.
4

A: slightly better clothing texture; neither pic really does anything for me, though.
5

B: slightly thiccer, dress construction makes more sense.
6

A: better head proportions, cool necklace; otherwise both are dull.
7

A: better head proportions, clothing texture, and background details.
8

Tossup. A has better clothing detail, B is slightly prettier and just a hair thiccer.
9
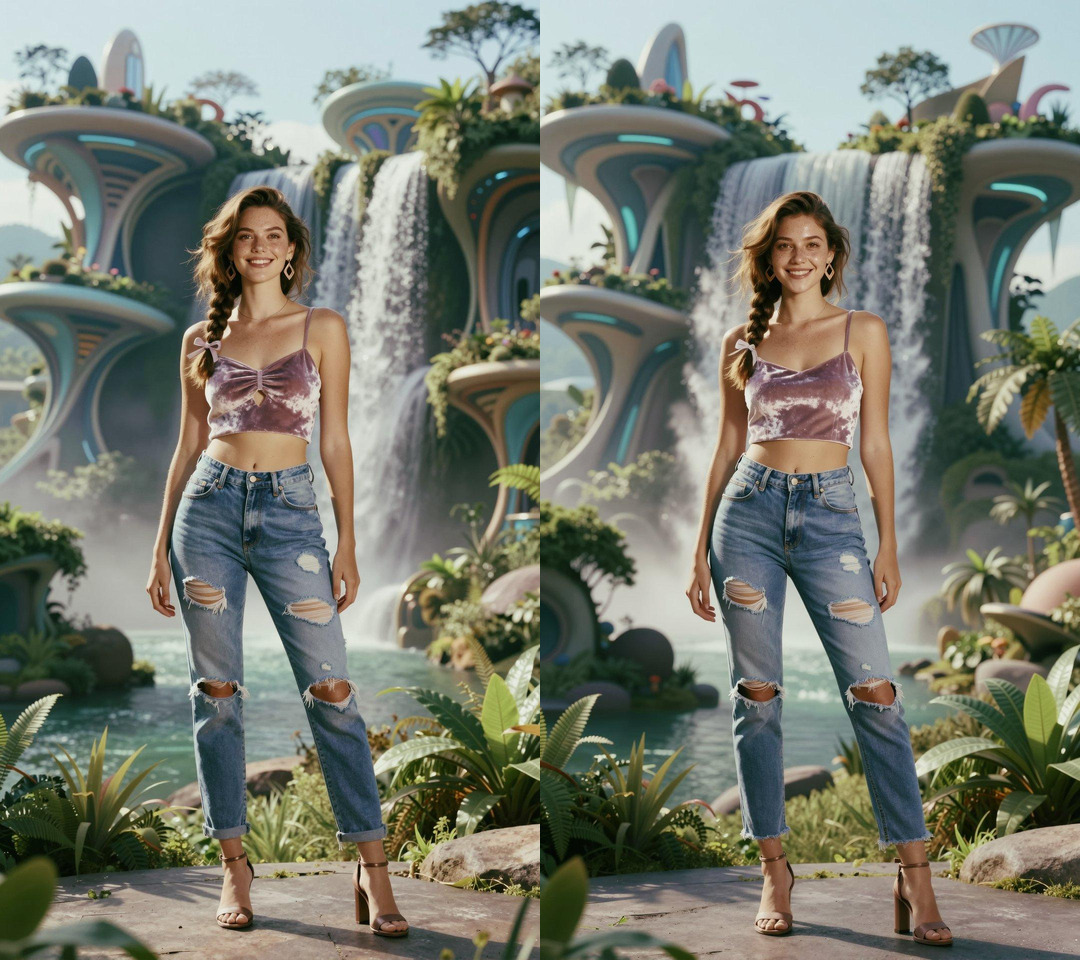
Both are fine; A has a more interesting top, but B wins because it frames her in the waterfall.
10

A: okay, this one is an obvious reject, but even though B has a left foot (attached), A wins because her head is proportional and she’s prettier, with catchlights.
11

B: vastly better skin tones, catchlights, has a left hand.
12

B: neither is great; A has more sensible arm placement, but B has less mottling on the skin and dress.
13

Both are fine. A has wider eyes, slightly better hair, and a more interesting “Space Force Nurse” look to the outfit, but B has a nice smile and much more interesting background architecture.
14

B: just because it has less of the stupid paint-splatter effects.
15

B: more interesting background, more interesting outfit, and more lively expression.
16

B: I think the head’s a bit too big, but the dress makes more sense.
17

A: better clothing texture and details; otherwise not a fan of either.
18

Both are fine, but A wins just because the fishnet connects top and bottom. No idea why there’s random text on the skirt, though.
19

B: A’s face just doesn’t work for me.
20
Saving the best for last! 😁

Seriously, the proportions are just wrong here, so it’s a reject. A has better clothing detail, but B has a cooler background with the second waterfall.
“1girl: don’t leave home without it”
Today I Learned that ZIT’s training data must include a lot of credit-card images.

Comments via Isso
Markdown formatting and simple HTML accepted.
Sometimes you have to double-click to enter text in the form (interaction between Isso and Bootstrap?). Tab is more reliable.